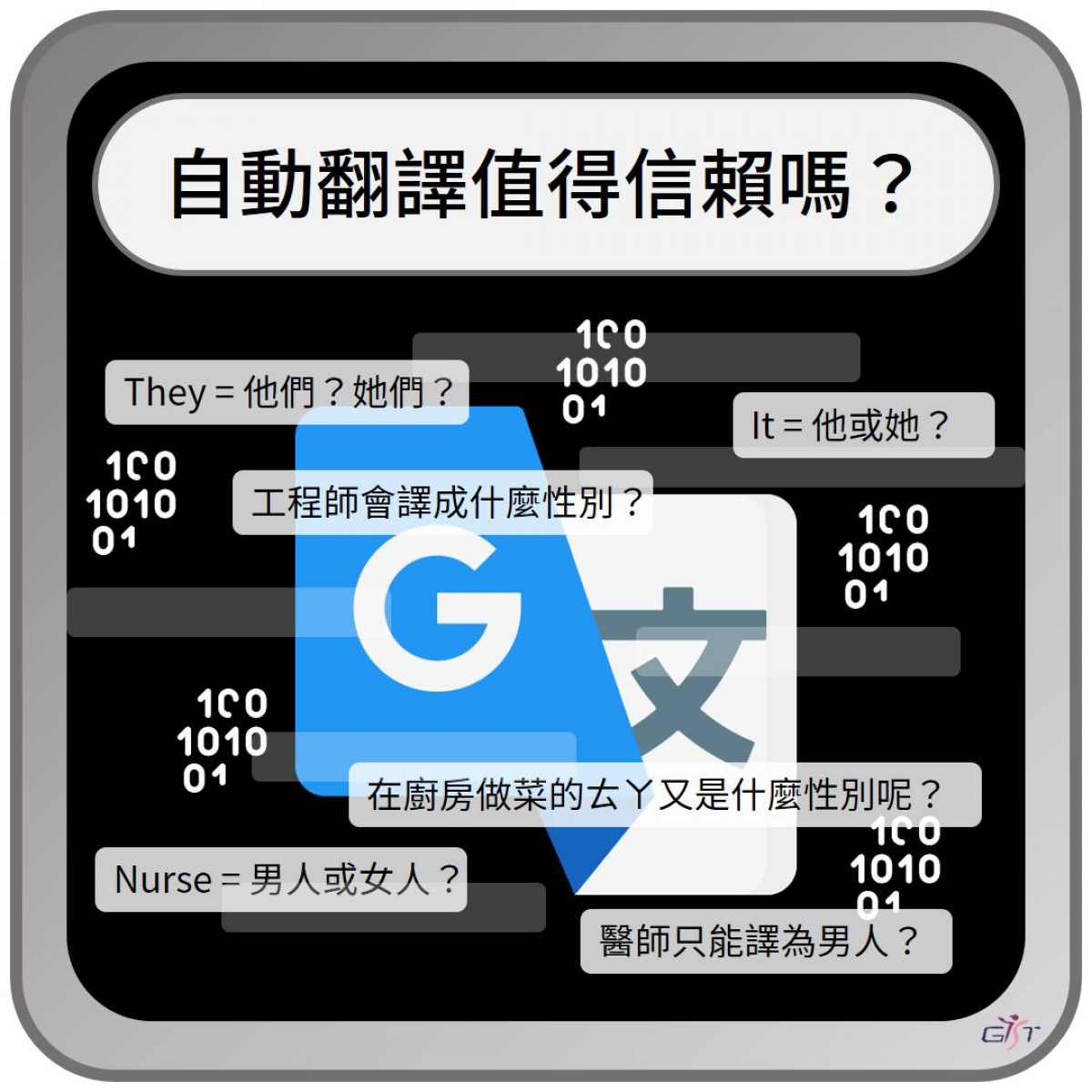
✹ 語料庫中的性別落差,造成翻譯系統以陽性詞稱呼女性
機器翻譯系統需要透過大型的語料庫(也就是收錄大量文本的電子資料庫)進行訓練。一份研究發現,Google Books當中的英文陽性代名詞出現頻率比陰性代名詞更多,尤其在1960年代出版的書籍中,前者曾多達後者的四倍。這種情形很有可能造成翻譯系統經過學習後,錯誤地使用陽性代名詞來指涉女性。
由於代名詞的性別落差在近年持續下降,使得相關的語料庫逐漸走向平等,若自動翻譯經常將男性預設為標準,可能使網路中的男性代名詞大量增加,導致語料庫的性別落差又再次擴大。
✹ 研發演算法辨認社會性別
為了解決前述問題,史丹佛大學的「性別化創新」(gendered innovations)研究團隊建議,可研發一套演算法辨識被指涉對象的社會性別(文化面向的態度、行為與表現)。這套演算法進行的方式如下:
- 找出文中提及的所有實體。
- 決定個別實體是生命或非生命,及其社會性別(某些外文也可能以陰性或陽性詞彙指涉非生命實體,例如德文的「太陽」是陰性,「月亮」是陽性)、及數量(單數或複數)。
- 透過機率演算法,根據文本脈絡和個別實體的生命性、社會性別、及數量,歸納文中提及的實體。
✹ 納入性別中立語言,使機器翻譯更加包容與精確
若要更精確地翻譯性別,系統也可以進一步學習納入性別中立的語言。
一來,由於特定的語言當中具有中性的代名詞(例如土耳其語的「o」),如此能提供更貼切的翻譯。目前Google翻譯土耳其語的中性句「o bir doktor」,會同時顯示「她是醫師」與「他是醫師」。
另一方面,透過使用如「他們」或瑞典語中的「hen」等性別中立的代名詞,也能更加包容例如雙性人等非二元性別者。
延伸閱讀:
性別化創新基礎方法-機器學習 https://tinyurl.com/56mbmj2h
性別化創新案例研究-機器翻譯 https://tinyurl.com/mr2zrh29
科科性別已經有IG(@kekegender)了!在這裡: https://www.instagram.com/kekegender/
了解更多科研領域中的性別議題:https://tinyurl.com/22tjby8d(性別化創新中文網)
-
本文 科科性別〈如何避免自動翻譯把大家都變成「男人」?〉
(引自科科性別:https://www.facebook.com/photo?fbid=686642446801222&set=a.50257221187491)