數據說話:140 萬份樣本揭示的視覺鴻溝
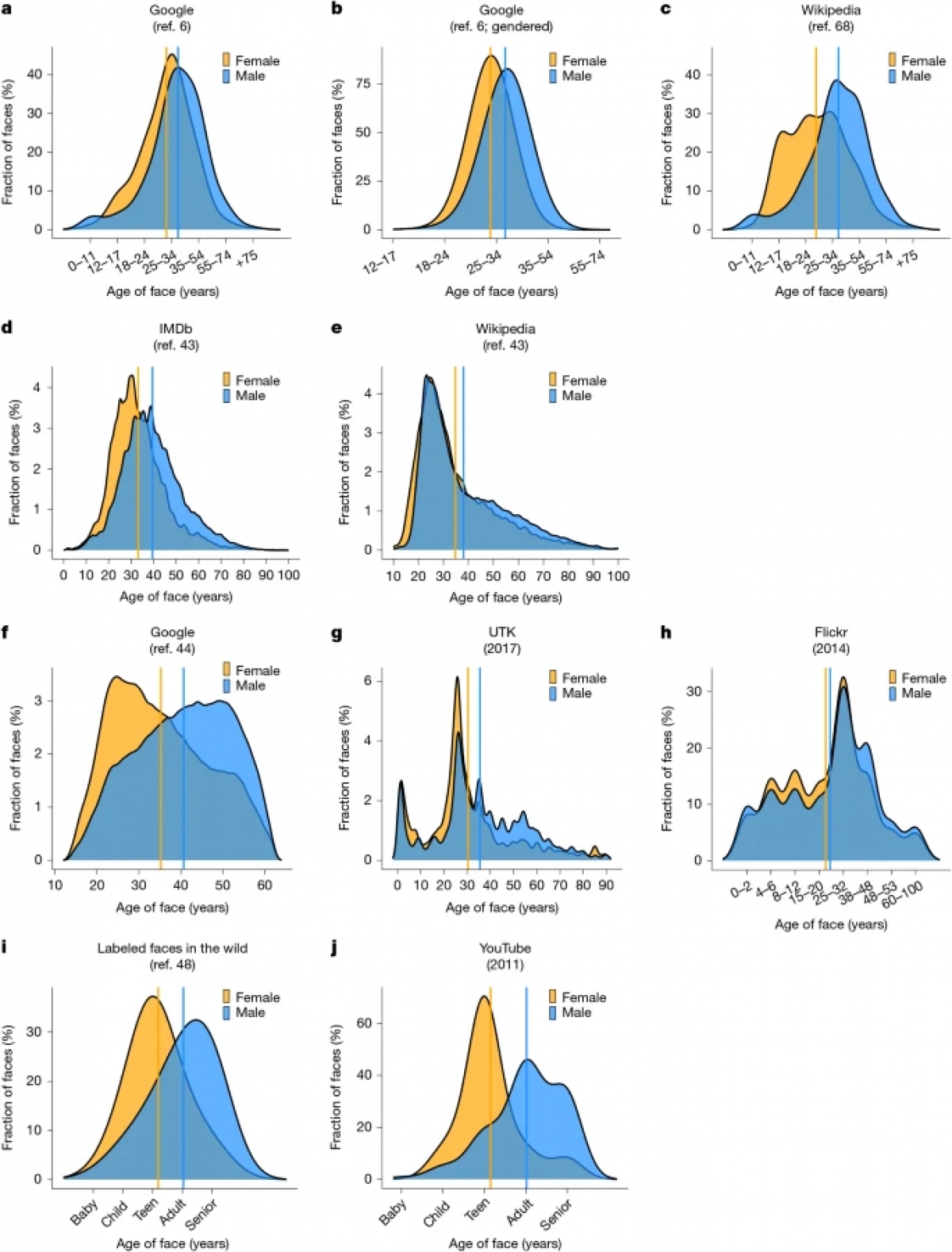
這項研究的規模極其宏大,分析了來自 Google、維基百科、IMDb、Flickr 和 YouTube 的 140 萬張圖像與影片,以及九個訓練自數十億網路詞彙的語言模型。該研究發現一個極為一致的現象:在各類職業與社會角色中,女性在線上媒體中普遍被呈現為比男性年輕。
根據客觀的數據分析,這種「年齡差距」在不同平台表現如下:
- IMDb 名人影像: 女性平均比男性年輕 6.5 歲。
- 維基百科: 女性平均比男性年輕 3.27 歲。
- Google 影像搜尋: 女性平均比男性年輕 5.35 歲。
- YouTube 影片: 被歸類為「年輕」的女性比例(33%)遠高於男性(20%)。
最令人震撼的是,研究將這些數據與美國人口普查(Census)的客觀事實進行比對。人口普查顯示,在現實職場中,男女之間並不存在系統性的年齡差異。然而,Google 影像卻呈現了誇張甚至反轉的趨勢。例如,在銷售與管理行業,現實中女性往往比男性資深,但在線上影像中,男性卻被呈現得比女性年長許多。這種扭曲在社會地位與收入較高的職業中尤為嚴重,顯示出數位環境正不斷強化「男性代表權威(年長)、女性代表青春」的刻板印象。
演算法的放大鏡:從 ChatGPT 到招聘偏好
研究進一步探討了這種偏見如何滲透進我們每日依賴的人工智慧系統。透過針對 ChatGPT (GPT-4o mini) 的履歷審核實驗,研究發現當要求 AI 生成或評估履歷時,它會自動假設女性申請人年齡更小(低 1.6 歲)、畢業年份更近(晚 1.3 歲)且相關工作經驗更少(少 0.92 歲)。
在評分階段,ChatGPT 展現出對年長男性的強烈偏好,認為其履歷品質更高。這種「演算法偏見」不僅反映了訓練數據中的社會偏見,更可能在實際的招聘流程中,為年長女性或年輕男性創造出不公平的「矽谷天花板」。
學術嚴謹性:不可忽視的研究限制
雖然這項研究提供了強而有力的證據,但研究團隊也誠實地指出了幾項重要的研究限制,這對於我們在解讀數據時至關重要:
- 二元性別框架: 研究承認性別是非二元的,但為了衡量與現有社會數據的對比,本研究受限於採用男性與女性的二元分類。
- 因果機制的複雜性: 由於數據量極大且屬觀察性質,目前仍難以斷定驅動這些關聯的具體心理機制——究其原因,是娛樂媒體的審美標準外溢到了職業領域,還是數據貢獻者(如維基百科編輯)的性別比例失衡所致?
- 地理與文化侷限: 實驗受試者主要為居住在美國的成年人,且基準測試主要對照美國人口普查數據,這意味著研究結果在全球不同文化背景下的普遍性仍有待驗證。
模型透明度: 研究主要針對開源模型(如 GPT-2)進行深度詞嵌入分析,而對於像 GPT-4 等閉源模型,僅能透過 API 進行有限的行為測試,難以完全解構其內部運作。
【小編說】給女科技人的思考:積極參與數位話語權
這篇文章對科技界的女性意義深遠。正如文中提到的「美麗稅」(Beauty Tax),女性常面臨必須「看起來年輕」的社會壓力,而這種壓力現在正被演算法固化。作為女科技人,我們不僅要警覺 AI 工具在招聘、升遷評估中可能存在的隱形偏見,更應積極參與 AI 的開發與監督。
研究建議,增加數據貢獻者的性別多元性(例如更多女性參與維基百科編輯或開源社群,請參考過去文章:薇姬的房間、台灣女子自由軟體工作小組)是緩解偏見的有效策略。這是一篇結合了巨量數據分析與深刻社會關懷的佳作,誠摯推薦給每一位關心科技平等與數位未來的讀者。